Unsupervised Learning of Shape Programs with Repeatable Implicit Parts
NeurIPS 2022
@inproceedings{progrip2022,
Author = {Boyang Deng and Sumith Kulal and Zhengyang Deng and Congyue Deng and Yonglong Tian and Jiajun Wu},
Title = {Unsupervised Learning of Shape Programs with Repeatable Implicit Parts},
booktitle={Advances in Neural Information Processing Systems},
year={2022},
}

Fig. 1: Our method represents an object as a shape program with repeatable implicit parts (ProGRIP). The program has two levels: the top level defines a set of repeatable parts (as latent vector $z_i$) and the bottom level defines all occurrences of each part with varying poses. The joint predictions, i.e., posed parts, are executed as posed implicit functions. Both the generation and the execution of ProGRIP are invariant to the order of predictions at both levels. ProGRIP can be learned without any annotations using our proposed matching-based unsupervised training objective.
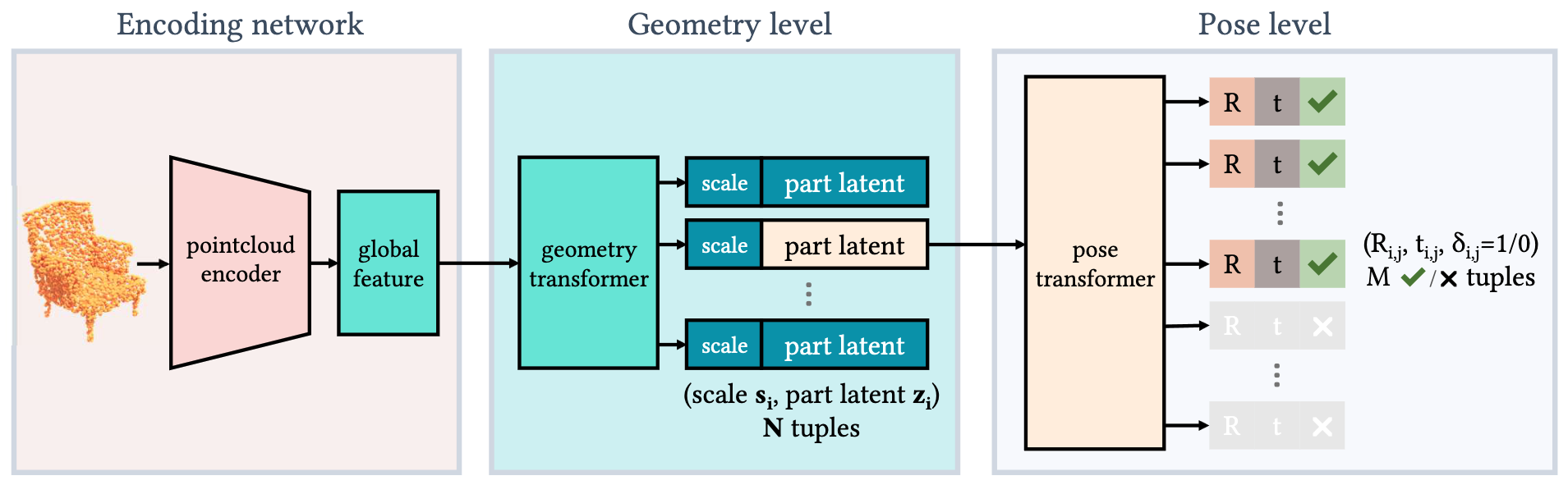
Fig. 2: Given a pointcloud, an auto-encoding architecture generates a ProGRIP composed of 2 levels of predictions. At the geometry level, our model predicts a set of $(s_i, z_i)$-pairs as the scales and deep latents of repeatable parts (middle); at the pose level, our model predicts a set of $(t_{i,j} , R_{i,j} , \delta_{i,j}$)-triplets as translations, rotations, and existence probabilities (right). Transformers are used at both levels for permutation invariant predictions.

Fig. 3: We execute each posed part (i.e., a $(s_i, z_i, t_{i,j}, R_{i,j}, \delta_{i,j})$ tuple) as a posed implicit function. A posed implicit function constructs an occupancy function $o_{i,j}$ to answer point queries $x$. For each query point $x$, we first canonicalise it using $(s_i, t_{i,j}, R_{i,j})$, then predict its occupancy conditioned on part latent $z_i$, and finally mask it by binarised existance $\delta_{i,j}$.

Fig. 4: On a task of fitting repeatable parts to a target shape, starting from the same initialization, the reconstruction loss (left) confines each posed parts to their initial local neighborhood and consequently prevents better parts arrangements. Conversely, our matching loss (right) match posed parts to local geometry of targets by shapes, thus rescue the part arrangement from the suboptimal local minima in reconstruction loss.
Fig. 5: Colors indicate the repeatable parts predicted by ProGRIP. Bottom: An explosive view with the parts dissected apart.
Fig. 6: Each color indicates a different semantic part predicted by ProGRIP.
Fig. 7: Shown here is a demonstration of interactive shape editing. In the two chairs show, ProGRIP enables switching arms from reference chair into target chair. This as simple as selecting arms from both chair with one click each. Then we replace the arm latents in the target chair with latents from the reference chair to get the shown output. Note how the orientation of the arms are correctly updated. This is due to our disentanglement of shape and pose. .